6 Loops en R. Paquete purrr

El paquete purrr tiene funciones útiles para seguir implementando la programación funcional en donde la filosofía a grandes rasgos es optimizar código quitando redundancia aplicando loops.
https://github.com/rstudio/cheatsheets/blob/main/purrr.pdf
Debemos instalar el paquete purrr:
install.packages("purrr", dependencies = TRUE)Seguiremos usando el conjunto de datos llamado iris:
6.1 map()
La función map es el simil de lapply y es una de las funciones más usadas en purrr. La función permite realizar iteraciones sobre una lista, array o vector y devuelve siempre una lista. Esto tiene varias ventajas, por ejemplo, que puedes guardar cualquier clase de R.

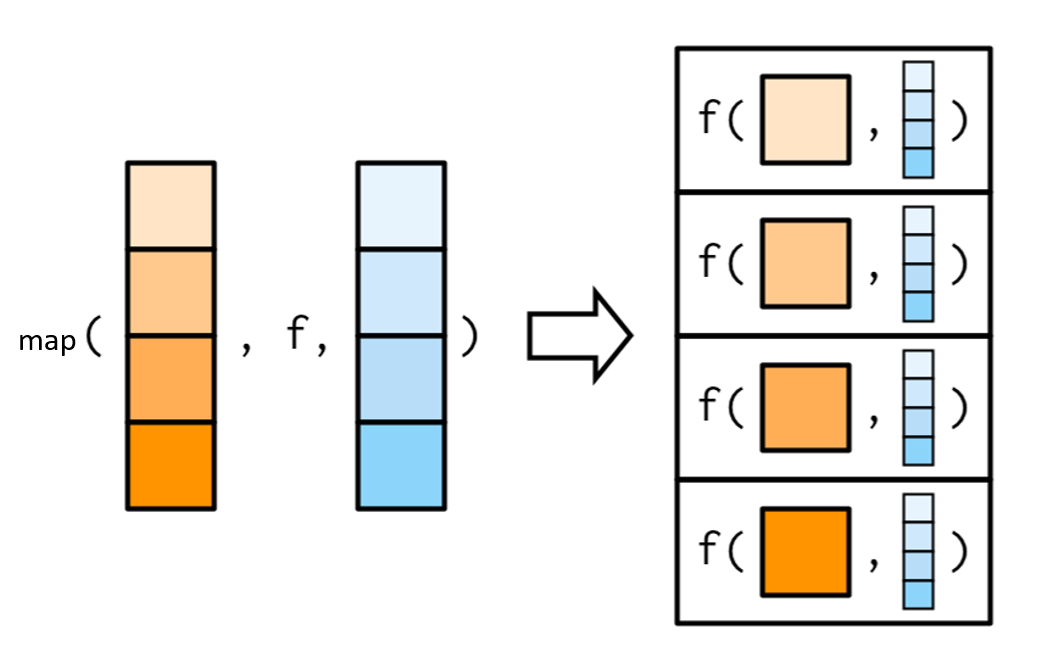
Vector como iteración
entrada <- 1:3
map(entrada, function(x){
x.1 <- iris[iris$Species == unique(iris$Species)[[x]],]
x.1 <- c("Especie" = as.character(unique(iris$Species)[[x]]),
"MSepal.Length" = mean(x.1$Sepal.Length),
"SDSepal.Length" = sd(x.1$Sepal.Length))
return(x.1)
})
#> [[1]]
#> Especie MSepal.Length SDSepal.Length
#> "setosa" "5.006" "0.352489687213451"
#>
#> [[2]]
#> Especie MSepal.Length SDSepal.Length
#> "versicolor" "5.936" "0.516171147063863"
#>
#> [[3]]
#> Especie MSepal.Length SDSepal.Length
#> "virginica" "6.588" "0.635879593274432"lista como iteración
Imaginemos que previamente hice un proceso donde separé las filas de cada especie y las guardé por separado en una lista.
entrada <- iris %>% split(iris$Species)
names(entrada)
#> [1] "setosa" "versicolor" "virginica"
class(entrada)
#> [1] "list"Ahora la lista tiene tres data.frames con los datos de cada especie y la usaremos como entrada en la función map. La lista tiene 3 elementos por lo que hará 3 iteraciones. En la iteración 1 tomará el primer data.frame de la lista, en la iteración 2 el segundo data.frame de la lista y en la iteración 3 tomará el tercer data.frame de la lista.
ejemplo <- map(entrada, function(x){
x.1 <- data.frame("Especie" = as.character(unique(x$Species)),
"MSepal.Length" = mean(x$Sepal.Length),
"SDSepal.Length" = sd(x$Sepal.Length))
return(x.1)
})
ejemplo
#> $setosa
#> Especie MSepal.Length SDSepal.Length
#> 1 setosa 5.006 0.3524897
#>
#> $versicolor
#> Especie MSepal.Length SDSepal.Length
#> 1 versicolor 5.936 0.5161711
#>
#> $virginica
#> Especie MSepal.Length SDSepal.Length
#> 1 virginica 6.588 0.6358796Colapsar la lista
Ya que la lista de salida tiene data.frames con columnas con el mismo nombre podemos colapsarlos en un único data.frame usando la función do.call() y rbind(), la ultima indica de que forma se puede colapsar la lista en este caso rbind indica que las apile por filas, de tal forma que las columnas se mantienen integras y lo único que incrementa son las filas.
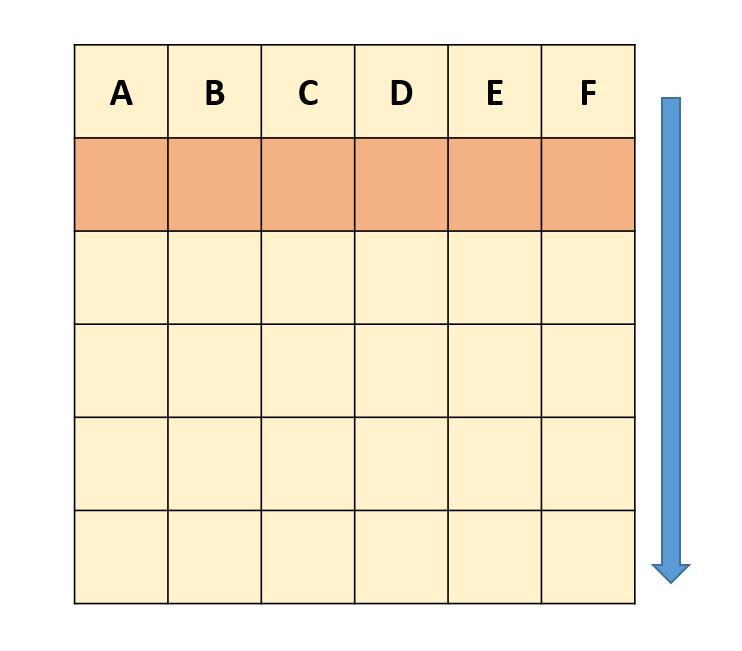
Antes es importante quitar los NULL. En ocasiones cuando algo no ocurre como deseamos en lugar de dejar que falle el loop guardamos el resultado como un NULL, así sabemos que los NULL dentro de nuestra lista son errores. Por ejemplo, supongamos que no queremos tener información de setosa porque sabemos que la información es incorrecta, así que aplicaremos una iteración y cuando lleguemos a esa especie devolverá un NULL.
ejemplo <- map(entrada, function(x){
if(unique(x$Species) == "setosa"){
x.1 <- NULL
} else {
x.1 <- data.frame("Especie" = as.character(unique(x$Species)),
"MSepal.Length" = mean(x$Sepal.Length),
"SDSepal.Length" = sd(x$Sepal.Length))
}
return(x.1)
})
ejemplo
#> $setosa
#> NULL
#>
#> $versicolor
#> Especie MSepal.Length SDSepal.Length
#> 1 versicolor 5.936 0.5161711
#>
#> $virginica
#> Especie MSepal.Length SDSepal.Length
#> 1 virginica 6.588 0.6358796Ahora antes de hacer un do.call() necesitamos quitar el elemento NULL de nuestra lista. En este ejemplo es sencillo porque tenemos solo tres elementos pero imaginemos su importancia cuando tengamos docenas, cientos o miles de elementos en nuestra lista.
Para quitar los NULL podemos recurrir a las funciones base de R:
Filter(Negate(is.null), ejemplo)
#> $versicolor
#> Especie MSepal.Length SDSepal.Length
#> 1 versicolor 5.936 0.5161711
#>
#> $virginica
#> Especie MSepal.Length SDSepal.Length
#> 1 virginica 6.588 0.6358796O podemos usar la función compact de purrr
compact(ejemplo)
#> $versicolor
#> Especie MSepal.Length SDSepal.Length
#> 1 versicolor 5.936 0.5161711
#>
#> $virginica
#> Especie MSepal.Length SDSepal.Length
#> 1 virginica 6.588 0.6358796
ejemplo <- compact(ejemplo)
do.call(rbind, ejemplo)
#> Especie MSepal.Length SDSepal.Length
#> versicolor versicolor 5.936 0.5161711
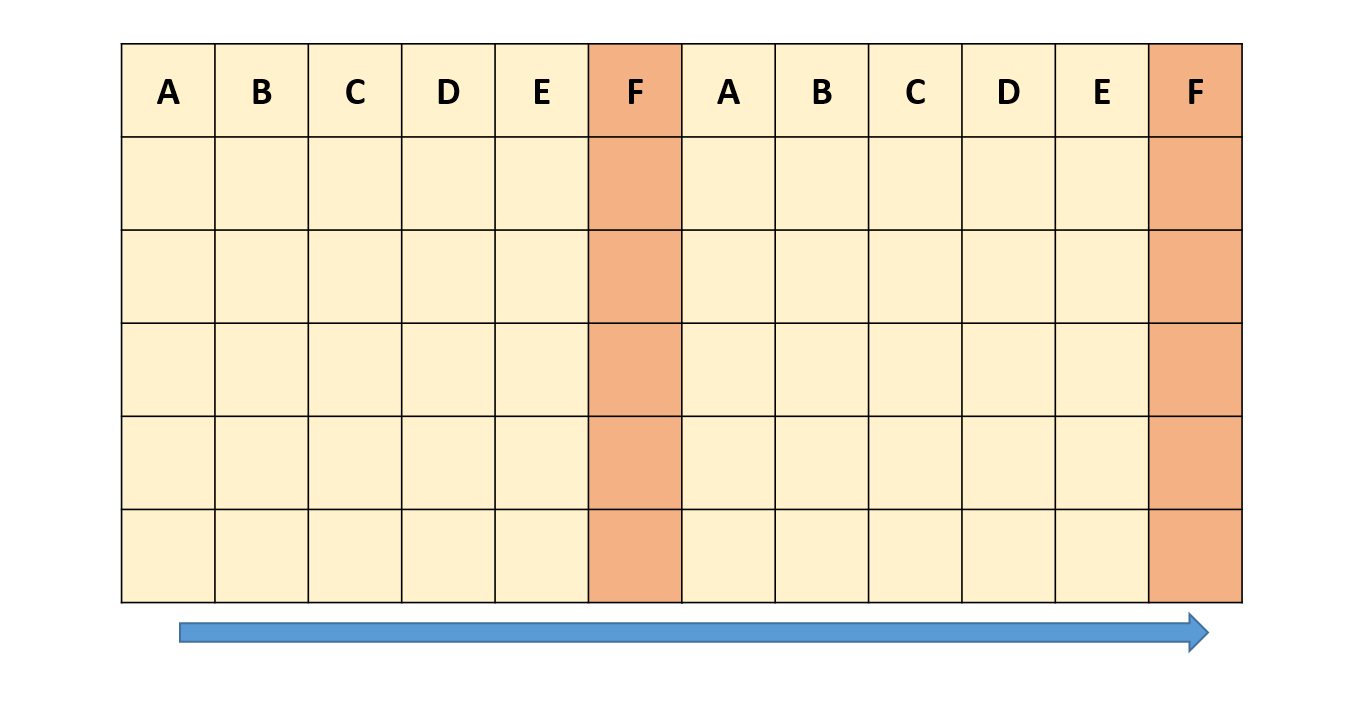
#> virginica virginica 6.588 0.6358796También podríamos colapsar la lista por columnas usando la función cbind, de tal forma que la única fila que tenemos se queda integra y lo que cambia es el no. de columnas.
do.call(cbind, ejemplo)
#> versicolor.Especie versicolor.MSepal.Length
#> 1 versicolor 5.936
#> versicolor.SDSepal.Length virginica.Especie
#> 1 0.5161711 virginica
#> virginica.MSepal.Length virginica.SDSepal.Length
#> 1 6.588 0.63587966.2 map_dfr y map_dfc
Para ahorrarnos el paso de usar la función do.call() para colapsar las listas en un data.frame podemos usar las funciones map_dfr() y map_dfc().
Es igual a la función map (i.e., tiene la misma estructura y trabaja con vectores, listas, arrays) pero la salida siempre es un data.frame lo que implica que en las instrucciones que aplicas en cada iteración el resultado siempre debe ser un data.frame. Si la salida es un vector numérico, un vector de caracteres, una lista, array u otra clase entonces te marcará un error.
6.2.0.1 map_dfr()
En nuestro ejemplo anterior, esta función sustituye el do.call(rbind, ejemplo).
Nota. Dejaremos setosa.
Usando una lista
map_dfr(entrada, function(x){
x.1 <- data.frame("Especie" = as.character(unique(x$Species)),
"MSepal.Length" = mean(x$Sepal.Length),
"SDSepal.Length" = sd(x$Sepal.Length))
return(x.1)
})
#> Especie MSepal.Length SDSepal.Length
#> 1 setosa 5.006 0.3524897
#> 2 versicolor 5.936 0.5161711
#> 3 virginica 6.588 0.6358796Usando un vector
map_dfr(1:3, function(x){
x.1 <- iris[iris$Species == unique(iris$Species)[[x]],]
x.1 <- c("Especie" = as.character(unique(iris$Species)[[x]]),
"MSepal.Length" = mean(x.1$Sepal.Length),
"SDSepal.Length" = sd(x.1$Sepal.Length))
return(x.1)
})
#> # A tibble: 3 x 3
#> Especie MSepal.Length SDSepal.Length
#> <chr> <chr> <chr>
#> 1 setosa 5.006 0.352489687213451
#> 2 versicolor 5.936 0.516171147063863
#> 3 virginica 6.588 0.6358795932744326.2.1 map_dfc()
En nuestro ejemplo anterior, esta función sustituye el do.call(cbind, ejemplo).
Usando una lista
map_dfc(entrada, function(x){
x.1 <- data.frame("Especie" = as.character(unique(x$Species)),
"MSepal.Length" = mean(x$Sepal.Length),
"SDSepal.Length" = sd(x$Sepal.Length))
return(x.1)
})
#> New names:
#> * `Especie` -> `Especie...1`
#> * `MSepal.Length` -> `MSepal.Length...2`
#> * `SDSepal.Length` -> `SDSepal.Length...3`
#> * `Especie` -> `Especie...4`
#> * `MSepal.Length` -> `MSepal.Length...5`
#> * `SDSepal.Length` -> `SDSepal.Length...6`
#> * `Especie` -> `Especie...7`
#> * `MSepal.Length` -> `MSepal.Length...8`
#> * `SDSepal.Length` -> `SDSepal.Length...9`
#> Especie...1 MSepal.Length...2 SDSepal.Length...3
#> 1 setosa 5.006 0.3524897
#> Especie...4 MSepal.Length...5 SDSepal.Length...6
#> 1 versicolor 5.936 0.5161711
#> Especie...7 MSepal.Length...8 SDSepal.Length...9
#> 1 virginica 6.588 0.6358796Usando un vector
map_dfc(1:3, function(x){
x.1 <- iris[iris$Species == unique(iris$Species)[[x]],]
x.1 <- c("Especie" = as.character(unique(iris$Species)[[x]]),
"MSepal.Length" = mean(x.1$Sepal.Length),
"SDSepal.Length" = sd(x.1$Sepal.Length))
return(x.1)
})
#> New names:
#> * `` -> `...1`
#> * `` -> `...2`
#> * `` -> `...3`
#> # A tibble: 3 x 3
#> ...1 ...2 ...3
#> <chr> <chr> <chr>
#> 1 setosa versicolor virginica
#> 2 5.006 5.936 6.588
#> 3 0.352489687213451 0.516171147063863 0.635879593274432¿Y si tenemos NULL de salida o un error en el proceso?
6.3 map_dbl, map_chr y map_lgl
Este grupo de funciones realiza iteraciones sobre una lista, array o vector y devuelve siempre un vector numérico (map_dbl), carácter (map_chr) o lógico (map_lgl).

6.3.2 map_chr()
map_chr(entrada, function(x){
x.1 <- unique(as.character(unique(x$Species)))
return(x.1)
})
#> setosa versicolor virginica
#> "setosa" "versicolor" "virginica"6.3.3 map_lgl()
map_lgl(entrada, function(x){
x.1 <- unique(as.character(unique(x$Species))) == "setosa"
return(x.1)
})
#> setosa versicolor virginica
#> TRUE FALSE FALSE6.4 walk()
La función Walk() es igual que map pero el resultado no se muestra, es útil cuando en cada iteración guardas, gráficas imprimir algo y no tienes interés en crear un objeto nuevo que gaste memoria RAM.
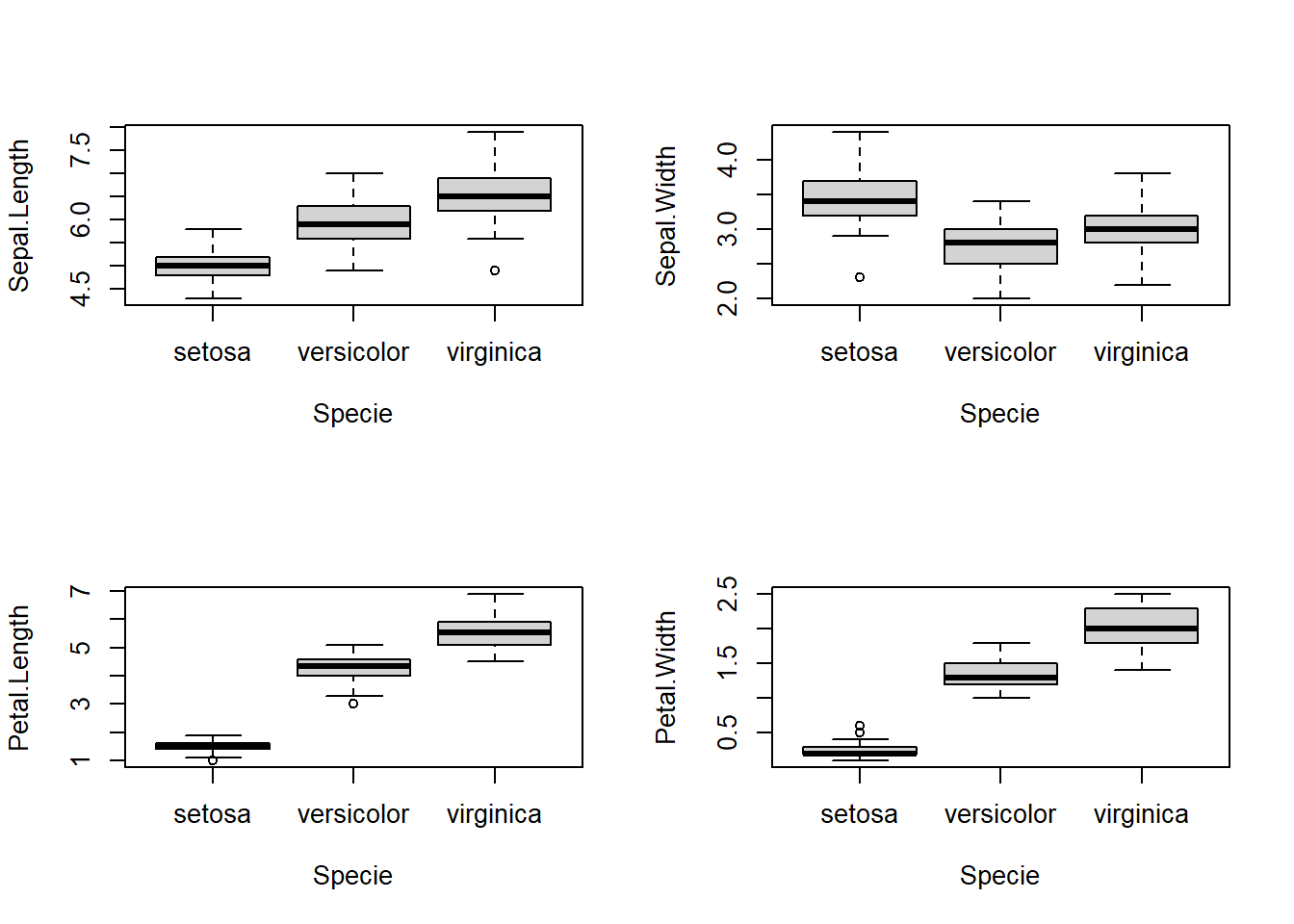
par(mfrow=c(2,2))
walk(1:4, function(i){
boxplot(iris[[i]] ~ iris$Species, ylab = names(iris)[i], xlab = "Specie")
})
Sería el equivalente a la siguiente instrucción usando funciones base de R: